Creating Human-like Text with Contrastive Search and GPT-2
Autoregressive language models (LMs) can sometimes produce low-quality text. Specifically, they may create "degenerative expressions," phrases or sentences that are nonsensical, repeat themselves or have grammatical errors. Additionally, the text generated by these models can lack "semantic consistency," meaning that it doesn't always make sense in context or is not always related to the topic of the input text.
In a recent paper titled "Contrastive Search Is What You Need For Neural Text Generation," researchers introduced a new decoding method called contrastive search that aims to solve these problems.
Contrastive search is a powerful decoding method that aims to improve the performance of natural language generation (NLG) systems. It does this by utilizing the probability distribution predicted by the language model and the similarity to the previous context. By considering both elements, contrastive search helps maintain semantic coherence between the generated text and the prefix text and reduces the likelihood of model degeneration.
In other words, contrastive search allows the language model to generate more coherent, consistent text and is less likely to produce nonsensical or irrelevant information. Contrastive search has been evaluated on various benchmarks and found to significantly outperform previous decoding methods, in some cases even achieving a human-like performance on 12 of 16 languages.
In this blog post, we'll explore the background and mechanics of contrastive search, its improvements for text generation, and how you can use contrastive search in your current projects to get better output with no downsides. But first, let's discuss why it is hard for language models to produce semantically coherent texts.
Why is it hard for language models to produce semantically coherent texts?
Autoregressive LMs are neural networks trained to generate text by learning the probability distribution of words in a given language. It is called autoregressive because the model uses the previous words to predict the next word in the sequence based on the underlying distribution.
However, this approach can lead to some issues when it comes to generating semantically coherent text. This is because these LMs are trained to maximize the probability of the next word without considering the semantic context and meaning of the words.
If you have already played with GPT-3 or other language models, you know these problems. If you haven't, here are examples of coherent and incoherent text produced by GPT-3:
- Coherent: "The cat sat on the mat. It looked up at me and meowed."
- Incoherent: "The cat sat on the mat. It flew to the moon and meowed."
Ideally, language models should always produce semantically coherent text, meaning text that is logical, makes sense, follows the rules of grammar and vocabulary, and conveys a clear and consistent message or idea. But creating a semantically coherent text is no easy task, and several challenges can make it difficult for LMs:
- Understanding the context: Generating semantically coherent text requires a deep understanding of the context in which the text will be used and sometimes even involves background knowledge or experiences.
- Vocabulary: AI models need a vast and accurate vocabulary to understand and generate text that makes sense.
- Handling ambiguities: Natural language is full of ambiguities, like homonyms or polysemes, meaning that a word can have different meanings depending on the context.
- Coherent structure: Generating text with a coherent structure requires the model to understand the grammatical rules of the language, maintain consistency in style, and avoid errors like punctuation mistakes or awkward phrasing.
- Maintaining consistency: The model may need help keeping track of the context or maintaining the focus on a particular topic throughout the text.
Sometimes, the issue is the model itself because some models can be anisotropic. In the context of language models, anisotropy refers to the model's inability to fully grasp and accurately represent the nuances and complexity of the language it's trying to model. This can lead to subpar performance and inaccurate predictions. In the next section, we'll dive deeper into the topic of anisotropy and explore it in greater detail.
What do isotropy and anisotropy mean?
In simple terms, isotropy refers to a uniform distribution of data in the representation space of a language model. In contrast, anisotropy refers to a non-uniform distribution where certain areas have more influence than others.
The representation space of a language model is the set of vectors or embeddings that represent the words or phrases in the model. In an isotropic representation space, all the vectors for different words or phrases are spread out evenly in the space.
This means that any two vectors are roughly the same distance from each other. This allows for fair comparison of words and phrases, leading to more accurate and meaningful representations.
Anisotropic representation space is a representation space in which the vectors are not evenly distributed. This can cause the model to rely more heavily on certain words or phrases, negatively impacting the coherence and consistency of the text and making it difficult for the model to generalize to new inputs.
We can compare the isotropy and anisotropy representation space to a library. An isotropic representation space is like a well-organized library, where the books are neatly arranged and placed in alphabetical order, allowing anyone to find the desired book easily. An anisotropic representation space is like a disorganized library where the books are scattered and placed haphazardly, making it challenging to find the right book.
In the following image, you can see the isotropy of different versions of GPT-2. The research team utilized the same input sentence ("Cambridge is a beautiful city.”) to examine the token representations of each model. They employed the cosine similarity matrix, a metric that measures the similarity between token representations, to visualize the data distribution in each model's representation space.
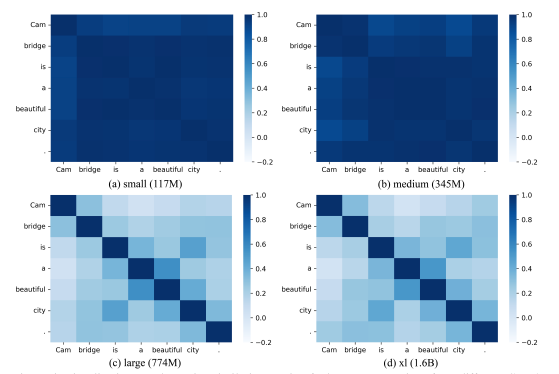
Cosine similarity matrix of token representations from different GPT-2 models. Source: https://arxiv.org/pdf/2210.14140.pdf
The results revealed that the representation space for the small and medium GPT-2 models (top) was anisotropic, meaning that data was not evenly distributed, and certain areas of the space had more influence or were more densely populated.
The representation space for the large and xl GPT-2 models (bottom) is evenly distributed and isotropic, meaning that no specific areas had more influence or were more densely populated.
What is the cause of anisotropy in language models?
Anisotropy in language models can be caused by a variety of factors, including:
- Insufficient training data: When a model is trained on a limited amount of data, it may not have the opportunity to understand the nuances and complexity of the language fully.
- Data bias: Biased training data can lead to a model that cannot accurately represent specific topics.
- Simple architecture: Some models have architectures that need to be more complex to represent the intricacies of natural language effectively.
Why is an isotropy representation space essential for contrastive search to work well?
An isotropic representation space is essential for contrastive search because it allows for a fair comparison of words and phrases, leading to more accurate and meaningful search results. You will see why this is the case when we explore the contrastive search algorithm later.
In the accompanying Google Colab notebook, I experimented with different GPT-2 models to explore the effect of anisotropy on the generated text. You can see clearly that the GPT-2 large model performs better than the GPT-2 medium model.
GPT-2 large output. Prefix: “DeepMind Company is”
DeepMind Company is a leader in artificial intelligence (AI). We have a long history of working with companies such as Google, Facebook, Amazon, and Microsoft to build products that improve people’s lives, and today we are excited to announce that DeepMind’s AlphaGo program has won the game of Go, becoming the first program to defeat a professional Go player.
GPT-2 medium output. Prefix: “DeepMind Company is”
DeepMind Company is one of the world’s leading AI companies. We are committed to building the world’s most advanced AI systems, and we are excited to work with you to build the best possible AI solutions for your business. We are looking forward to working with you to build the best possible AI solutions for your business.
Now that we have covered the basics, let's delve deeper into the different decoding methods, such as contrastive search, to better understand how they work.
Contrastive Search vs. Deterministic & Stochastic Decoding Methods
Decoding is a crucial step in NLP that enables the generation of human-readable text from a machine-readable representation, such as a vector or a probability distribution. This process aims to translate the encoded information into semantically coherent texts.
There are different decoding methods, such as deterministic and stochastic methods. Deterministic methods tend to output the exact text given the same input, while stochastic methods generate text based on a probability distribution and have a degree of randomness.
Many decoding methods are available, such as beam search, top-k sampling, and nucleus sampling. These methods can vary in flexibility and control over the output text. Some methods allow for more customization and control, while others focus on generating text similar to a given input or following specific patterns.
Before we discuss the benefits of contrastive search, it is essential to understand how current methods work. Knowing this will help us understand why contrastive search is an improvement over traditional methods.
Current Methods: Deterministic & Stochastic Decoding
Greedy decoding is a typical example of a deterministic decoding method, which chooses the word with the highest probability at each step. Greedy decoding is fast and straightforward to implement, but it can lead to suboptimal results because it does not consider the context of the entire sentence.
Stochastic methods, such as sampling from the probability distribution, can generate more diverse and creative text, but they are not guaranteed to produce coherent or grammatically correct text. This is because the model only considers the probability of the next word based on the previous words without considering the text's overall meaning or context.
The new decoding method: Contrastive Search
The contrastive search method aims to improve the performance of natural language generation (NLG) systems by utilizing both the probability distribution predicted by the language model and the similarity to the previous context.
The following image shows examples of different decoding methods and their results.
Texts generated by a GPT-2-large model using different methods given the prefix "Kobe Bryant is." Source: https://arxiv.org/pdf/2210.14140.pdf

To generate this text, the researchers used the GPT-2 large model with the prefix "Kobe Bryant is." Beam search with a beam width of 5 generated text that contains undesirable repetitions (highlighted in red). Nucleus sampling, with a probability of 0.95, quickly veered off topic and talked about other players that were inconsistent with the prefix (highlighted in blue). The text generated by contrastive search was semantically coherent to the prefix while being grammatically fluent.
A Closer Look at Contrastive SearchContrastive
The contrastive search algorithm has two main components. The first component is the probability of the candidate word predicted by the language model - this is called model confidence. The second component measures how different a candidate word is from the previous words in the context — this is called the degeneration penalty.
The degeneration penalty is calculated by finding the maximum similarity between the representation of the candidate word and all the words in the previous context. The hyperparameter α regulates the balance between these two components.
V(k) is the set of top-k predictions from the language model's probability distribution.
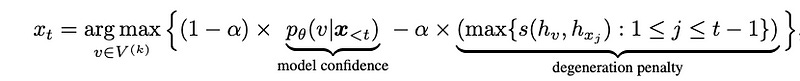
The Contrastive Search Algorithm. Source: https://arxiv.org/pdf/2210.14140.pdf
In other words, contrastive search aims to find unique and different candidate words semantically coherent with the prefix and avoid repetition and degeneration in the generated text. It uses the "model confidence" to measure how likely the candidate word is according to the language model and the "degeneration penalty" to measure how different the candidate word is from the previous context.
The researchers created a token similarity matrix to understand better how contrastive search works. This is a way to visually see how similar words are to each other in a text.
In the study, they compared contrastive search to greedy search by creating these matrices for both. They measured the cosine similarity between words by finding how alike their token representations (hidden states of the last layer of the transformer model) are. The results showed that contrastive search generated more diverse and semantically coherent text, while greedy search generated more repetitive and less coherent text.
You can see the results of the greedy search at the top and the contrastive search at the bottom in the figure below.
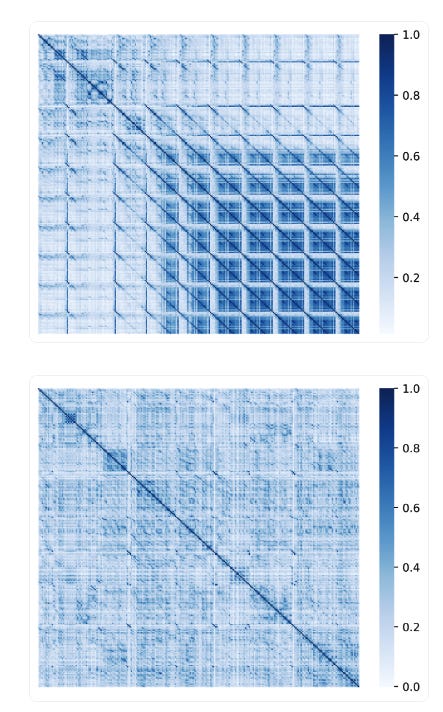
Token similarity matrix of greedy search (top) and contrastive search (bottom). Source: https://arxiv.org/pdf/2210.14140.pdf
In the result of the greedy search, we can see many high similarity scores in the off-diagonal entries, meaning that there are a lot of repetitions in the generated text. In contrast, in the result of the contrastive search, the high similarity scores mostly appear on the diagonal entries, indicating fewer repetitions in the generated text.
Now that we have a basic understanding of contrastive search and how it works let's look at how to use it with the Huggingface Transformers library.
Using Contrastive Search with the Huggingface Transformers Library
The Huggingface Transformers library implements contrastive search in version 4.24.0 and above. To use contrastive search with a GPT-2 model, we must install the library and load the language model.
We will compare different decoding methods with each other, and we will also compare the performance of contrastive search with small and large GPT-2 models to get an idea of how the isotropy of the model affects the quality of the generated text.
You can find the Google Colab Notebook, containing the entire source code and all examples, here.
To get started, let's first install the Huggingface Transformers library and PyTorch:
%%bash
pip install torch
pip install "transformers>=4.24.0"
Once the library is installed, we can load the GPT-2 model with the following command:
import torch
from transformers import AutoTokenizer, GPT2LMHeadModel, GPT2Tokenizer
device = "cuda:0" if torch.cuda.is_available() else "cpu"
model_name = 'gpt2-large'
model = GPT2LMHeadModel.from_pretrained(model_name)
model = model.to(device)
Now that we have the GPT-2 model loaded, we can generate texts. We use the same prompt as before: "DeepMind Company is."
tokenizer = AutoTokenizer.from_pretrained(model_name)
input_ids = tokenizer('DeepMind Company is', return_tensors='pt').to(device).input_ids
# Deterministic Method
output = model.generate(input_ids, max_length=128)
output = tokenizer.decode(output[0], skip_special_tokens=True)
"""Output:
DeepMind Company is a leading AI research company, with a focus on deep learning and deep learning-based systems.
The company's research is focused
on the development of deep learning-based systems that can learn from large amounts of data, and that can be used to solve real-world problems.
DeepMind's research is also used by the UK government to develop new technologies for the UK's National Health Service.
DeepMind's research is also
used by the UK government to develop new technologies for the UK's National Health Service.
DeepMind's research is also used by the UK government to
develop new technologies
"""
You can see that the deterministic method leads to an output that repeats itself over and over again.
# Stochastic Method
output = model.generate(input_ids, do_sample=True, max_length=128, top_p=0.95, top_k=0)
output = tokenizer.decode(output[0], skip_special_tokens=True)
"""Output:
DeepMind Company is credited with creating AlphaGo, a supercomputer developed by DeepMind's London-based AI lab in 2015 that defeated the world's best
Go player, Lee Sedol of South Korea, by putting his brain into a computer. This may not seem like very serious, but it is a big accomplishment given
that human supercomputers have been developing neural networks for decades and have increasingly become faster than traditional supercomputers.
According to Per Bortnikov, the head of research at AI specific OOO, "We are once again seeing the development of the first supercomputer of the new
wave of computers."
In fact
"""
The text generated by the stochastic methods does not suffer from repetition but instead becomes incoherent and needs more semantic relevance.
# Contrastive Search
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name, pad_token_id=tokenizer.eos_token_id)
model = model.to(device)
model.eval()
inputs = tokenizer('DeepMind Company is', return_tensors='pt').to(device).input_ids
output = model.generate(input_ids, penalty_alpha=0.6, top_k=4, max_length=128)
output = tokenizer.decode(output[0], skip_special_tokens=True)
"""Output:
DeepMind Company is a leader in artificial intelligence (AI). We have a long history of working with companies such as Google, Facebook, Amazon, and
Microsoft to build products that improve people's lives, and today we are excited to announce that DeepMind's AlphaGo program has won the game of Go,
becoming the first program to defeat a professional Go player.
The victory is a testament to the power of deep learning, and to the incredible work
of our research team, which has been at the forefront of AI research for the past five years. AlphaGo is one of the most advanced Go programs ever
created, and its performance is
"""
Contrastive search is better than traditional decoding methods. It generates semantically consistent text with the prefix and avoids repetition and degenerative phrases.
As previously mentioned, contrastive search requires an isotropic model for optimal performance. To demonstrate this, let's use an anisotropic GPT-2 model with the same input as before and compare the outputs.
# Contrastive Search
model_name = "gpt2-medium"
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name, pad_token_id=tokenizer.eos_token_id)
model = model.to(device)
model.eval()
inputs = tokenizer('DeepMind Company is', return_tensors='pt').to(device).input_ids
output = model.generate(input_ids, penalty_alpha=0.6, top_k=4, max_length=128)
output = tokenizer.decode(output[0], skip_special_tokens=True)
"""Output:
DeepMind Company is one of the world's leading AI companies. We are committed to building the world's most advanced AI systems, and we are excited to
work with you to build the best possible AI solutions for your business.
We are looking forward to working with you to build the best possible AI solutions for your business.
"""
Compared to the GPT-2 large model, the results using a smaller model are clearly worse. The smaller, anisotropic model tends to repeat itself frequently. However, as the researchers have shown, this issue is specific to small GPT-2 models and does not affect larger models.
You can test this for yourself by replacing GPT-2 with the OPT model from Facebook and repeating the experiments: (https://github.com/yxuansu/SimCTG#contrastive_search_with_opt). You'll find that even smaller OPT models can produce sound output with contrastive search.
Conclusion
To wrap up, we discussed contrastive search, a new decoding method for natural language generation that aims to improve upon traditional methods by considering both the probability distribution predicted by the language model and the similarity to the previous context.
We covered the traditional methods' challenges in generating semantically coherent text and how contrastive search addresses these issues. We also looked at examples of using contrastive search with the huggingface transformers library.
Additionally, we highlighted the importance of using an isotropic model for optimal performance of contrastive search and the potential performance degradation when this is not the case.
Overall, contrastive search is a promising method for improving the performance of natural language generation systems by maintaining semantic coherence and reducing the likelihood of model degeneration.
Resources:
- Tian Lan**, Generating Human-level Text with Contrastive Search in Transformers,** 2022**,** https://huggingface.co/blog/introducing-csearch
- Yixuan Su, GMFTBY, Eunkwang Jeon, A Contrastive Framework for Neural Text Generation, 2022, https://github.com/yxuansu/SimCTG
- Yixuan Su, Nigel Collier, Contrastive Search Is What You Need For Neural Text Generation, 2022, https://arxiv.org/abs/2210.14140
Google Colab Notebook: